위의 자료를 참고하여 작성하였다.
▶웹과 웹 크롤링
- 웹(Web)
World Wide Web(www)의 줄임말. 인터넷에 연결된 전세계 사용자들이 서로의 정보를 공유할 수 있는 장소이다.
※인터넷: 컴퓨터 네트워크 통신망
2. 웹 브라우저(Web Browser)
HTML로 작성된 웹 페이지를 탐색하고 보는 데 사용되는 소프트웨어이다.
※HTML(Hypertext Markup Language): 웹은 HTML 언어로 작성된다. 크롬, 사파리 등이 있다.
3. 웹 크롤링과 웹 스크래핑
웹 크롤링: 인터넷 상에 존재하는 모든 웹 페이지를 방문하여 데이터를 수집하는 방법이다. 즉, 싹 다 긁어오는 것으로 볼 수 있다!
- 인터넷 상의 모든 페이지를 방문하며, 각 페이지의 링크를 따라가면서 자동으로 데이터를 수집
- 특정한 웹 페이지가 아닌 URL을 타고다니며 반복적으로 데이터를 가져오는 과정(데이터 색인)
- 대부분의 검색 엔진에서 사용된다.
- 예시: 구글, 네이버 같은 검색 엔진의 검색 결과를 보여줌
웹 스크래핑: 특정한 웹 사이트에서 필요한 데이터를 수집하는 방법이다. 원하는 부분만 선택적으로 추려내는 것이다!
- 좁은 범위의 데이터 수집
- 예시: 온라인 쇼핑몰에서 상품 정보를 추출, 뉴스 사이트에서 최신 기사를 수집 등
※웹 크롤링 준비: 크롬과 크롬 드라이버
웹 크롤링을 할 때는 크롬 브라우저를 사용하는 것이 좋다!
크롬 버전을 확인해서 최신 버전인지 확인해준다.
우측 상단 점 3개 -> 도움말 -> Chrome 정보

예전에는 크롬 드라이버를 매번 크롬 버전에 맞춰서 설치해주어야 했지만 이제는 더이상 따로 설치하지 않아도 된다!
▶HTML과 CSS
여기서는 최소한의 필요한 부분만 살펴보도록 하겠다.
HTML
HTML 구조 : 태그로 감싸진 속성과 내용들의 모음
※ 태그: HTML 요소라고도 부르며, HTML 문서를 구성하는 기본 단위이다.

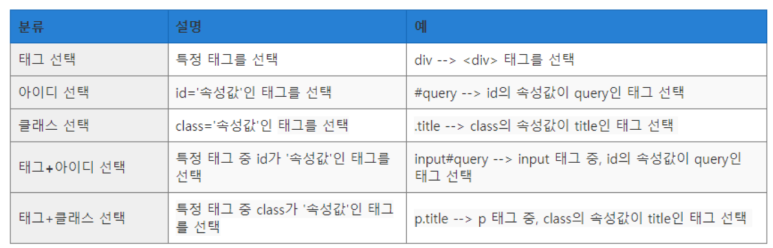
- 태그 이름: 다양한 종류와 의미를 가진 태그들이 있는데 다 외울 필요는 없고 필요 시 아래 표를 참고해서 웹 크롤링을 진행하면 된다.

- 속성명: html은 수 많은 태그로 이루어져 있어서 동일한 태그가 무수히 많이 사용된다. 따라서 각 태그들을 구분해주기 위해서 속성을 부여해준다. 아래 2가지 속성은 꼭 기억하자!
① ID: 하나의 웹페이지 당 하나만 쓸 수 있는 고유한 이름
<태그이름 id = "속성값">
② CLASS: 비슷한 형태를 가진 요소에 여러 번 사용할 수 있는 이름
<태그이름 class = "속성값">
- 속성값과 내용: 프로그래머에 따라 다르다.
CSS
HTML로 만들어진 밋밋한 화면을 예쁘게 꾸며주는 역할을 한다.
즉, HTML 특정 태그를 지목해서 속성값(글자색, 크기, 폰트, 배경색 등)을 넣어주는 것!
-> css가 특정 태그를 지목하는 방식(규칙)을 알게되면 원하는 데이터를 감싸고 있는 태그를 지목해서 그 안의 데이터를 가져올 수 있다.
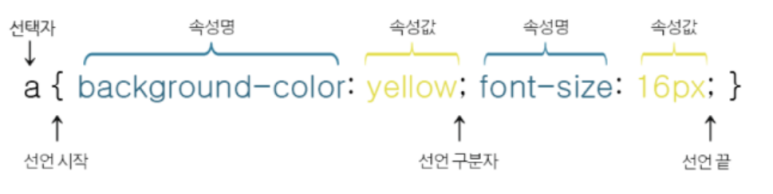
CSS 구조
CSS 코드는 위와 같이 선택자와 선언부로 구성된다.
여기서 선택자에 더 주목해야한다!
▶정적/동적 웹 페이지
- 정적 웹 페이지
웹 서버에 미리 저장된 파일이 그대로 전달되는 웹페이지. 즉, 특정 웹페이지의 url 주소만 주소창에 입력하면 웹 브라우저로 HTML 정보를 마음대로 가져다 쓸 수 있는 것이다.
※ 동적 웹 페이지와 다르게 url주소 외에는 아무것도 필요없다!
<예시>
① 네이버 검색창에 아무 단어나 검색한다. 여기선 유튜브를 검색해보았다.
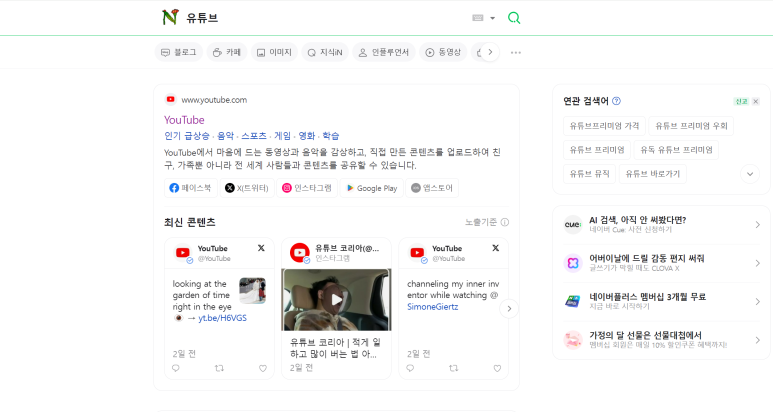
② 검색 결과의 url을 복사하고 다시 주소창에 해당 url을 입력하면 처음 검색 결과와 동일한 페이지를 볼 수 있다.

검색 결과 url 복사

주소창에 해당 url 입력
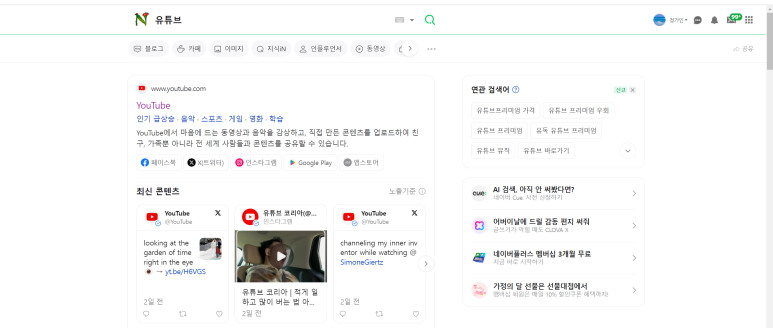
처음 검색 결과와 동일한 페이지
2. 동적 웹 페이지
url만으로는 들어갈 수 없는 웹 페이지를 말한다.
-> 혹시 들어가지더라도 url의 변화가 없는데도 실시간으로 내용이 계속해서 추가되거나 수정된다면 동적 웹 페이지이다.
※ 무언가를 클릭해서 페이지가 변경되는 것은 다른 경우!
<예시>
① 로그인을 해야만 접속 가능한 네이버 메일
② 보고 있는 위치에 출력 결과와 url이 계속 변하는 네이버 지도
③ 드래그를 아래로 내리면 계속 새로운 사진과 영상이 나타나는 인스타그램과 유튜브
▶정적/동적 수집
정적 페이지에서 정보를 수집 하느냐, 동적 페이지를 하느냐에 따라서 사용되는 파이썬 패키지는 달라진다. 간단히 표로 정리해보면 아래와 같다.
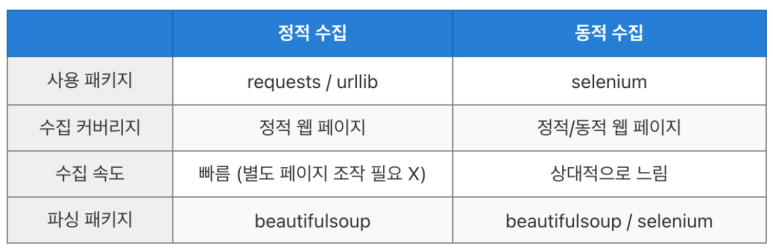
▶정적 웹크롤링 - request / beautiful soup
정적 웹페이지의 데이터를 가져온다.
<방법>
1. 원하는 웹페이지의 html문서를 싹 긁어온다.
2. 긁어온 html 문서를 파싱한다.
※파싱(Parsing) : 특정 형식으로 구성된 데이터를 분석하고 그 의미를 이해하는 과정이다.
주로 텍스트 기반 데이터를 해석하거나, 프로그래밍 언어의 소스 코드를 이해하거나, 문서를 구조화하고 내용을 추출하는 데 사용된다.
3. 파싱한 html 문서에서 원하는 것을 골라서 사용한다.
정적 웹크롤링 관련 패키지
다음은 위의 3단계를 수행하기 위해 사용되는 패키지이다.
Step 1. requests
html 문서를 가져올 때 사용하는 패키지이다.
<설치 방법>

VS CODE의 터미널창에 위와 같이 입력한다. 아나콘다를 사용한다면 pip 대신 conda를 입력해도 된다.

설치 완료!

사용 방법
Step 2. BeautifulSoup4
매우 길고 정신없는 html 문서를 잘 정리되고 다루기 쉬운 형태로 만들어 원하는 것만 가져올 때 사용된다. 이 작업을 파싱이라고도 한다!

설치 완료!


실습
Step 3. BeautifulSoup4 (find/select)
이 3단계가 정적 크롤링의 핵심인 필요한 정보의 위치와 구조를 파악해서 가져오는 단계이다.
정적 크롤링을 위해선 매우 중요한 단계이다! (아래 2가지 함수 중 2번째인 select 함수를 사용하는 것이 더 직관적이고 쉽다.)
① find(). find_all()함수
find() : 하나만 찾는 함수
find_all(): 모두 다 찾는 함수
- 괄호 안에는 html의 태그나 속성이 들어간다.
- 주의할 점은 find로 찾는 것이 여러 개라면 가장 첫번째 것만 가져온다는 점이다!

입력 예시

사용 코드
② select(), select_one() 함수
각각 find_all(), find()와 같은 개념이다.
다만, 괄호 안에 CSS 선택자를 넣어 원하는 정보를 찾는다.

사용 코드
▶정적 웹크롤링 - 텍스트, 하이퍼링크, 이미지 가져오기
- 크롤링 할 페이지(url) HTML 가져오기
정적 웹크롤링 방법 중 1,2단계(html 문서 싹 긁어와서 파싱)에 해당하는 코드이다.
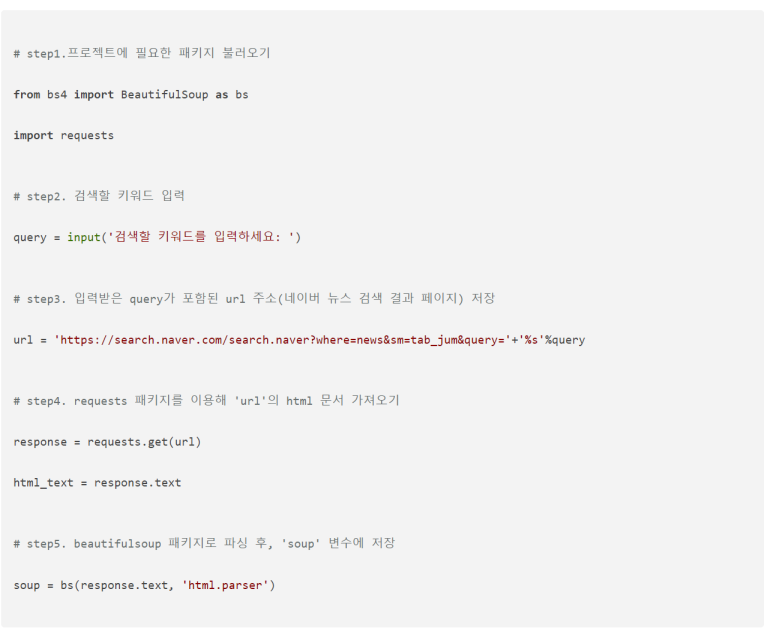
※여기서 url 주소는 네이버 뉴스 검색창 그대로!
2. 크롤링 할 페이지 실제로 들어가서 추출한 HTML 확인하기
위와 같이 실습하면 터미널 창에 "검색할 키워드를 입력하세요:" 라고 출력된다. 여기에 원하는 검색 키워드를 입력한다.
① 텍스트 추출: .get_text()
Step 1. 개발자 도구에서 커서 모양의 아이콘 클릭
Step 2. 추출을 원하는 부분, 여기서는 뉴스 제목을 클릭
Step 3. 해당 부분의 HTML 태그를 분석하여 select() 함수로 추출

여기서 css selector은 a.news_tit이다.
css selector을 알아냈다면 select 함수에 입력하여 원하는 부분의 html을 변수에 저장해주고 for문과 .get_text() 함수를 이용하면 된다!

코드

실행 결과
② 링크 추출 : .attrs['href']
속성을 가져오는 함수이다. href 속성은 위에서 가져온 new_titles 변수에 저장되어 있으므로 따로 한번 더 가져올 필요 없이 바로 for문을 작성한다.

코드

실행 결과
③ 이미지 추출: .attrs['src']
1. 이미지 주소(src)를 가지고 있는 html을 news_thumnail 변수에 저장
2. 이미지 다운로드를 위해서 해당 주소들을 리스트(link_thumnail)에 append 함수를 이용해 하나씩 삽입
3. 사진을 다운로드 받아서 내 PC에 저장하기 위해서 저장할 폴더를 만들고, src 주소를 이용해 다운로드
※폴더 생성에는 os 모듈과 urllib.request 패키지의 urlretrieve 함수가 필요하지만 모두 다 파이썬 내장 라이브러리이므로 따로 설치해주실 필요 없이 import 해주면 된다.

코드

실행 결과
'2024 SWLUG > 파이썬 프로젝트 - 크롤러' 카테고리의 다른 글
| 검색/크롤링/스크래핑 (0) | 2024.05.22 |
|---|---|
| 웹크롤링(2) (0) | 2024.05.22 |
| 파이썬 개발환경 구축 (0) | 2024.05.22 |